背景
我一直想把在CSDN上面发布的文章保存到本地,然后迁移到简书上,但是CSDN比较闭塞的就是不提供迁移接口。所以我只能寻找第三方工具,但是发现要么已经失效,要么就是使用不太友好(对我个人而言),所以我用go语言花了半小时自己撸了一个导出工具。
分析
我们先来分析如何获取到文章信息:
1.获取文章地址
首先我们通过文章列表获取文章的地址。
<h4 class="">
<a href="https://blog.csdn.net/yang731227/article/details/103007106" target="_blank">
<span class="article-type type-1 float-none">原创</span> Beego脱坑(六)——使用模板获取数据 </a>
</h4>
可以发现 每篇的文章地址 在 h4标签 下面的a 标签中。
2.获取文章内容
接着我们获取文章的具体内容,CSDN的文章类型有两种,一种是富文本类型,还有一种是markdown。因此我先查看它们显示的方式是否一样
首先我查看的是富文本格式的文章,发现内容是在<article class="baidu_pl">标签里面:
<article class="baidu_pl">
<!--忽略文章内容-->
</article>`
接着我们在找一篇markdown格式编写的文章查看下,发现内容依然是在<article class="baidu_pl">标签里面。
3.查找接口
找到文章内容在什么标签内还没完事,我这人比较喜欢搞事情。因为我希望能到把博客导成md格式,但是现在网页上爬取的内容都是html,也就是富文本格式。因此我去寻找go语言 html转markdown 的库,但是不幸的是没有找到。虽然又工具可以帮我完成这份工作,但是我比较懒希望能减少工作就减少一点。
然后我的思维又开始拐弯,如果是md格式的文章,我们在文章的编辑界面不是可以直接获取到md文本吗?我在编辑页面把所有的md文章,都直接保存为md不就能省很多功夫?
但是接下来我去查看编辑页面源代码的时候,没有发现文章的内容。这时候不要慌!那么它肯定是通过某个接口来加载数据的,查看下XHR果然发现了一个接口,参数是文章ID。https://mp.csdn.net/mdeditor/getArticle?id=103007106
新的接口为:
https://blog-console-api.csdn.net/v1/editor/getArticle?id=103007106
以此类推,我再去打开富文本文章的编辑界面,我希望它也是通过接口加载数据的,这样在进行数据处理的时候我就能够省很多代码。然鹅富文本格式并没有接口数据。
但是我这个人比较轴,我就想试下,我把接口ID改成富文本文章的ID,看看它是否能够为我传来数据,果然有的时候搞开发就要有折腾的精神,我成功得到了文章内容 。https://mp.csdn.net/mdeditor/getArticle?id=82253319
https://blog-console-api.csdn.net/v1/editor/getArticle?id=82253319
两个数据不一样的地方就是,如果是md文章,它 markdowncontent 里面的内容是 md文本,如果是富文本的文章,它markdowncontent属性就为空,因此我们在导出文本的时候,如果遇到markdowncontent不为空就获取markdowncontent的内容并保存为.md ,如果遇到为空的情况,就获取content内容并保存为.html
4.整理
现在我们已知 https://blog-console-api.csdn.net/v1/editor/getArticle?id=xxxx
这个接口可以获取到文章的信息,参数是文章ID。
所以接下来我们需要做的就是,通过爬虫模拟csdn登录状态,获取所爬的博客中每篇文章的ID,传递给接口,获取文章标题和内容,并根据格式保存不同的文件。
实现代码
使用到的第三方库
- 使用
goconfig库,来加载配置信息,用来获取博客地址、文章列表页数和Cookie。 - 使用
goquery进行爬虫
model.go
package models
import (
"CSDN/utils"
"github.com/Unknwon/goconfig"
)
var ArrDetailID []string //保存文章ID
var BlogUrl string // 配置博客地址
var Cookie string // 配置Cookie
var TotalPage int // 博客文章列表总页数
type Article struct { //用来解析json
Data struct {
// ID string `json:"id"`
Title string `json:"title"`
// Articleedittype int `json:"articleedittype"`
// Description string `json:"description"`
Content string `json:"content"`
Markdowncontent string `json:"markdowncontent"`
/*
Tags string `json:"tags"`
Categories string `json:"categories"`
Channel string `json:"channel"`
Type string `json:"type"`
Status int `json:"status"`
ReadType string `json:"readType"`
UseVipView int `json:"use_vip_view"`
UseFansView int `json:"use_fans_view"`
Reason string `json:"reason"`
ResourceURL string `json:"resource_url"`
OriginalLink string `json:"original_link"`
AuthorizedStatus bool `json:"authorized_status"`
CheckOriginal bool `json:"check_original"`
SelfRecommend bool `json:"selfRecommend"`
*/
} `json:"data"`
}
func init() {
runpath := utils.GetRunPath()
cfg, err := goconfig.LoadConfigFile(runpath + "/conf/conf.ini")
if err != nil {
panic("没有加载到配置文件")
}
BlogUrl, err = cfg.GetValue("csdn", "blogurl")
if err != nil {
panic("blogurl错误")
}
Cookie, err = cfg.GetValue("csdn", "cookie")
if err != nil {
panic("cookie错误")
}
TotalPage, err = cfg.Int("csdn", "totalpage")
if err != nil {
panic("totalpage错误")
}
}
csdn.go
package transaction
import (
"CSDN/models"
"encoding/json"
"github.com/PuerkitoBio/goquery"
"io/ioutil"
"log"
"net/http"
"strings"
"time"
)
func GetHtml(url string) *http.Response {
client := &http.Client{ //要管理HTTP客户端的头域、重定向策略和其他设置,创建一个Client
Timeout: time.Second * 2,
}
req, err := http.NewRequest("GET", url, nil) //NewRequest使用指定的方法、网址和可选的主题创建并返回一个新的*Request。
if err != nil {
log.Println(err)
}
req.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36") //模拟浏览器User-Agent
req.Header.Add("Cookie", models.Cookie)
resp, err := client.Do(req) //Do方法发送请求,返回HTTP回复
if err != nil {
log.Println(err)
}
return resp //返回网页响应
}
func GetdetailID(resp *http.Response) {
defer resp.Body.Close()
dom, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatalln(err)
}
dom.Find("h4").Each(func(i int, selection *goquery.Selection) {
time.Sleep(1 * time.Second) //防止访问次数过于频繁
detailurl, _ := selection.Find("a").Attr("href")
index := strings.LastIndex(detailurl, "/")
models.ArrDetailID = append(models.ArrDetailID, detailurl[index+1:])
})
}
func ParseArticleJson(jsonurl string) (string, string) {
resp := GetHtml(jsonurl)
defer resp.Body.Close()
resp_byte, _ := ioutil.ReadAll(resp.Body)
respHtml := string(resp_byte)
var article models.Article
json.Unmarshal([]byte(respHtml), &article)
title := article.Data.Title
content := article.Data.Content
markdown := article.Data.Markdowncontent
if markdown == "" {
return title + ".html", content
} else {
return title + ".md", markdown
}
}
utils.go
package utils
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strings"
)
func WriteWithIoutil(name, content string) {
data := []byte(content)
if ioutil.WriteFile(name, data, 0644) == nil {
fmt.Println("导出成功:", name)
}
}
// 获取程序当前运行路径
func GetRunPath() string{
file, _ := exec.LookPath(os.Args[0])
path, _ := filepath.Abs(file)
index := strings.LastIndex(path, string(os.PathSeparator))
runpath :=path[:index]
return runpath
}
main.go
package main
import (
"CSDN/models"
"CSDN/transaction"
"CSDN/utils"
"fmt"
"time"
)
func main() {
fmt.Println("设置成功,开始导出blog,时间较长请等待!!")
for i := 1; i <= models.TotalPage; i++ {
time.Sleep(800) //设置延时
url := fmt.Sprintf("%s/article/list/%d", models.BlogUrl, i)
resq := transaction.GetHtml(url)
transaction.GetdetailID(resq)
}
runpath := utils.GetRunPath()
for i := 0; i < len(models.ArrDetailID); i++ {
//jsonurl := fmt.Sprintf("https://mp.csdn.net/mdeditor/getArticle?id=%s", models.ArrDetailID[i])
jsonurl := fmt.Sprintf("https://blog-console-api.csdn.net/v1/editor/getArticle?id=%s", models.ArrDetailID[i])
name, content := transaction.ParseArticleJson(jsonurl)
utils.WriteWithIoutil(runpath+"/"+name, content)
time.Sleep(1000) //设置延时
}
}
conf.ini 配置文件
[csdn]
blogurl = https://blog.csdn.net/yang731227 ;博客地址
totalpage = 7 ;博客文章列表数
cookie = ;爬取账号的cookie
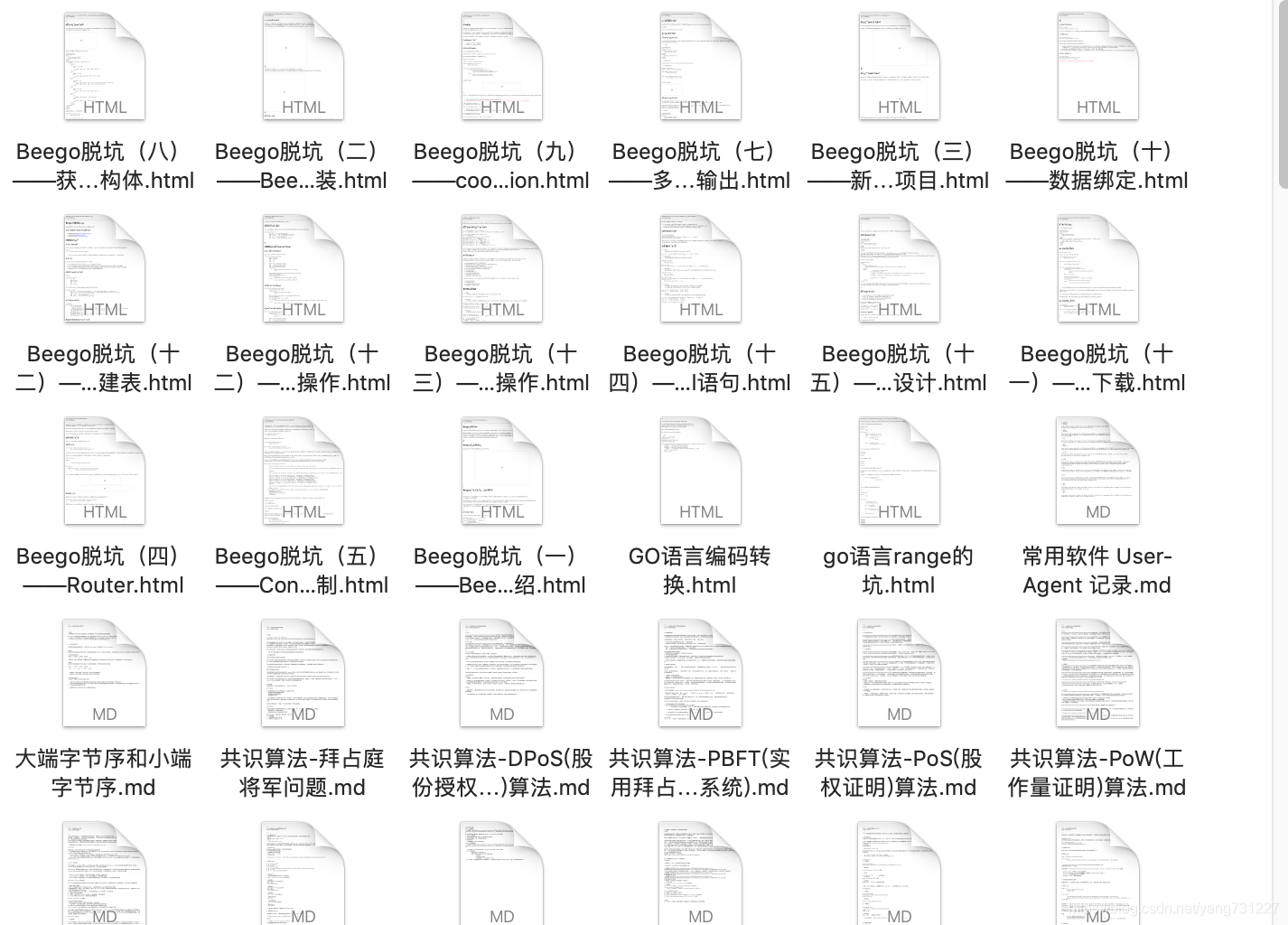
导出效果
下载
土豪通道:
- win: https://download.csdn.net/download/yang731227/12157060
- mac :https://download.csdn.net/download/yang731227/12154880
或者直接到github上面下载:
https://github.com/Clown95/CSDN-Blog-Export
如果你觉得对你有帮助给个star呗
本文转自 https://blog.csdn.net/yang731227/article/details/103098189,如有侵权,请联系删除。
部分资料来源于网络,版权属其原著者所有,只供学习交流之用。如有侵犯您的权益,请联系【公众号:码农印象】删除,可在下方评论,亦可邮件至ysluckly.520@qq.com。互动交流时请遵守宽容、换位思考的原则。

